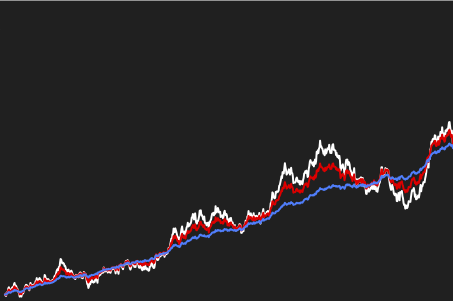
This lecture (10 ECTS) will lay the foundations of reinforcement learning. We will start gently with multiarmed bandits, then turn towards the theory of Markov decision processes which leads us to basic solution algorithms such as policy iteration, value iteration or (double) Q-learning. Finally, we will turn to policy gradient methods.
The lecture addresses classical concepts from probability theory, filling gaps from previous lectures and advancing towards continuous time stochastic processes. We will discuss martingales and their convergence theory, weak convergence theory (including a proof of the central limit theorem) and then proceed towards the Brownian motion (including the Donsker theorem).
Während sich in der Vorlesung “Stochastik I” mit Eigenschaften von Folgen von unabhängigen Zufallsvariablen beschäfftigt wurden, so steht in diesem Modul sogenannte Markovketten in diskreter Zeit im Vordergrund. Hierbei handelt es sich um stochastische Prozesse, bei dem der zukünftige Zustand nur vom aktuellen Zustand, nicht aber von der Vergangenheit abhängt. Markovketten in diskreter Zeit finden vielfältige Anwendungen in der Wahrscheinlichkeitstheorie, Statistik, Informatik und anderen Bereichen, z. B. bei der Modellierung von Warteschlangensystemen, Populationsdynamik oder Finanzmärkten.
Das Seminar bereitet Studierende (Bachelor-Master) auf ihre Abschlussarbeiten vor. Studierende bearbeiten Themen der Wahrscheinlichkeitstheorie oder des maschienellen Lernens, im Kontext der künstlichen Intelligenz. Das Seminar findet geblockt an 1–2 Terminen mit etwas Abstand zur Klausurenphase statt.
In order to improve performance and enhance the user experience for the visitors to our website, we use cookies and store anonymous usage data. For more information please read our privacy policy.